J’avais dit que je ne réagirais pas sur l’actualité, mais je le fais aujourd’hui de manière distancée sur une question récurrente en ce qui concerne l’anonymat sur les réseaux.
Cette question est trop souvent mal posée, sur un angle parfois simpliste qui consiste à considérer que l’anonyme est celui qui commente sans s’engager personnellement, et qui profite de son anonymat (relatif) pour écrire les pires horreurs en se pensant à l’abri d’une action en diffamation.
Il est alors tentant d’envisager une plus grande régulation… qui passerait par des vérifications d’identité ou des obligations de déclaration d’identité.
Je suis plutôt pour conserver les possibilités multi-identitaires du web comme principe de base. La transparence totale me paraît très problématique et peu propice à générer une diversité d’usages. Elle apparaît aussi risquée à plus d’un titre. J’avais déjà montré par le passé que même au sein de l’Education Nationale, on n’osait plus rien dire, notamment du temps où sévissait un directeur omnipotent à la Dgesco.
D’autre part, il me semble que l’anonymat de base ne signifie pas qu’il soit impossible d’échapper à la loi. On peut porter plainte contre un anonyme ou un pseudonyme. L’enquête de la justice parviendra peut-être à condamner l’intéressé si besoin est, et si elle parvient à retrouver l’identité principale. Ici, restent en suspens les possibilités techniques, éthiques et législatives de ce type d’action.
Mais le problème principal vient selon moi d’une poursuite de la crise de l’autorité qui s’est développée rapidement sur le web, mais qui est en fait une circonstance assez logique de la démocratisation de nos sociétés et de nos interfaces. J’en avais parlé en 2006 en montrant que la crise allait s’accentuer avec les nouveaux usages sur le web. J’étais reparti des travaux d’Hannah Arendt notamment ainsi que de sa définition :
«Le mot auctoritas dérive du verbe augere, «augmenter», et ce que l’autorité ou ceux qui commandent augmentent constamment, c’est la fondation. Les hommes dotés d’autorité étaient les anciens, le Sénat ou les patres, qui l’avaient obtenue par héritage et par transmission de ceux qui avaient posé les fondations pour toutes les choses à venir, les ancêtres, que les Romains appelaient pour cette raison les majores». (Arendt, la crise de la culture, 1989)
L’autorité permet justement d’asseoir une légitimité décisionnelle sans avoir recours à l’autoritarisme. Elle ne souffre pas de contestation.
Notre période politique montre bien cette volonté de contester les autorités même démocratiquement élues. On néglige à mon sens trop souvent que certains contestataires souhaiteraient substituer aux élus, une autorité différente. La référence au pouvoir militaire est souvent présente dans les discours, comme s’il fallait mettre en place une nouvelle autorité possédant une force armée pour ne plus être contestée. C’est malgré tout, un classique en démocratie, lorsque sa remise en cause aboutit à un totalitarisme dont les sources et l’énergie motrice sont clairement la haine des autres et leur désignation comme boucs émissaires.
Désormais, la question de l’autorité auctoriale est également en déclin. La plupart des messages sur les réseaux sociaux ne sont pas nécessairement produits sous une identité reconnue, on oscille plutôt entre pseudonymat et anonymat. On est clairement dans une logique distincte de l’autorité d’auteur au sens de celui fait œuvre.
Cette volonté régulière de dénoncer l’absence d’auteur renvoie au fait que cela détériore quelque peu la qualité de la source du message puisqu’il ne s’agit que d’une opinion qui repose a priori sur un pedigree difficile à évaluer.
Si régulièrement journaliste, politique ou intellectuel en vient à dénoncer cette logique d’un anonymat sans contrôle pour de plus ou moins bonnes raisons, cette question est évidemment la base du travail des services de renseignements, et ce depuis fort longtemps, et ce parce qu’avant les réseaux sociaux les publications sous pseudonymes ont toujours été monnaie courante, particulièrement sous des périodes difficiles, voire hostiles. Sur ce point, je renvoie à ce fameux ouvrage d’Adrien Baillet… qu’il signe sous le nom d’A.B…
Mais ce retour à la nécessité de l’autorité est un exercice sur lequel travaillent avec une certaine assiduité les leaders du web que sont Google ou Facebook notamment en ayant cherché à plusieurs reprises à limiter les identités annexes ou dissimulées, et ainsi pouvoir rattacher à des productions des identités dans un processus classique d’attribution de métadonnées à une ressource. Le réseau Google + visait à reproduire le modèle Google Scholar des profils de chercheurs à une échelle plus grande.
Les logiques de centralisation cherchent à garder non seulement un contrôle sur le contenu diffusé par des logiques de plateformes, mais également à veiller à ce que ces contenus puissent être rattachés à des « autorités » qui sont en fait ici des profils, mais qui correspondent aux « autorités » ou notices d’autorités telles qu’on les utilise dans nos systèmes documentaires.
Ce qui fait donc fantasmer les différentes instances (institutions traditionnelles et grandes plateformes décisionnelles de nos existences), c’est justement de pouvoir réaliser une identification fine de nos activités et productions, voire de pouvoir rassembler nos différentes identités. Pour cela la recherche de l’identifiant unique reste le Graal absolu. Élément pratique en apparence puisqu’il évite les multiconnexions, il peut s’avérer aussi un instrument de suivi. Un pharmakon en quelque sorte. Une nouvelle fois, ces questions ont déjà été envisagées au niveau scientifique. J’étais très favorable à un identifiant unique des chercheurs. Il existe désormais avec Orcid, mais d’autres tentatives ont été également amorcées et il n’est pas vain de se demander si le profil Google Scholar ne peut pas également en constituer un.
Nos adresses mail et IP font partie de ces données personnelles qui peuvent constituer des formes d’identifiant majeur. Désormais, le numéro de téléphone portable apparaît comme de plus en plus clef sur ces aspects.
Cela nous oblige à repenser nos existences au travers de nouvelles « propriétés » au sens de possessions, mais surtout au sens de qualités (eigenschaften) pour mieux nous définir et nous projeter dans les espaces semi-publics du web.
Je précise également, mais je le disais déjà dans du Tag au Like, que les instances de contrôle de nos existences comme Google et Facebook fonctionnent sur la popularité et qu’ils cherchent à renforcer leurs mécanismes de productions d’autorités avec des profils optimisés… ce qui suppose parfois aussi des classements voire des hiérarchies.
Au final, la situation est clairement celle d’une crise des autorités dans tous les sens du terme. Mais elle était totalement prévisible, et ce d’autant que la différence ancienne et déjà discutable entre réel et virtuel n’existe plus.
Nous sommes donc en déficit d’autorités sur plusieurs plans :
– au niveau institutionnel, notamment parce que depuis les premiers mythes du web, nous ne sommes pas parvenus à développer une démocratie participative efficace. Le reproche en est fait actuellement à la classe politique au pouvoir.
– au niveau des expertises. Sur ce point, règne une grande confusion, avec des tribuns médiatiques qui sont parfois des médiocres scientifiquement, voire purement et simplement des escrocs. S’en suit un mélange des genres entre opinions et analyses qu’il est souvent difficile de départager. La critique des médias se nourrit de ces dysfonctionnements, tout en produisant des visions encore plus idéologiques et doctrinaires que les médias qu’elle critique.
Une des critiques classiques du web et des interfaces numériques est qu’ils ont tendance à tout aplanir et à donner l’impression que tout se vaut.
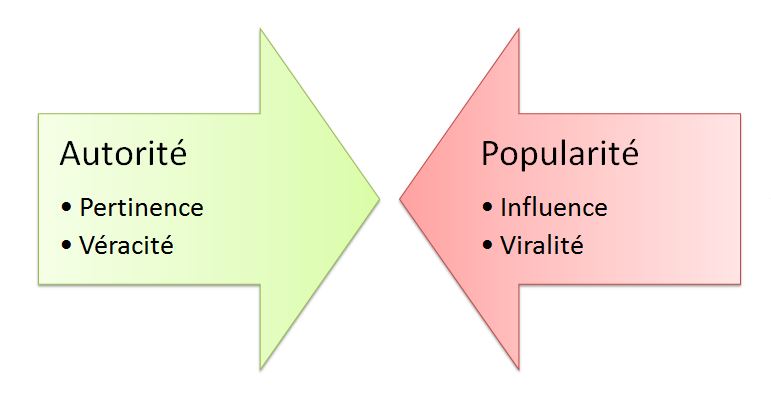
C’est ici que se situe probablement cette tension entre popularité et autorité, et qui marque le triomphe de l’influence sur la pertinence.
Le plus légitime devient celui qui obtient le plus de viralité.
C’est le troisième passage que je n’avais pas pleinement su décrire, même si j’avais commencé à travailler sur les théories du complot depuis bien longtemps, d’un point de vue historique initialement, puis au niveau informationnel par la suite.
La crise de l’autorité est aujourd’hui celle de l’affrontement entre viralité et véracité avec la confusion qui peut se produire avec la reprise d’éléments complètement erronés de façon plus nombreuse sur le web que celle qui contient pourtant la position la plus rationnelle scientifiquement.
Il est vrai que même l’histoire du web n’est pas épargnée avec la théorie d’une création militaire qui demeure encore trop fréquente… même chez les Dernier point sur lequel il me semble qu’il va falloir être très attentif : celui d’une remise en cause totale des institutions de savoir que sont les lieux d’enseignement et notamment les universités. J’ai toujours plaidé pour une position professorale qui puisse être discutée et corrigée par les étudiants durant les cours notamment lorsqu’il y a des critiques, des erreurs et des approximations -chercheurs. Toutefois, au sein de ces remises en cause drastiques de toutes les autorités, il n’y a aucune raison que l’université soit épargnée. Mais c’est sans doute le propos d’un autre billet.
")