Camille Alloing signalait sur Twitter la volonté de Facebook d’inciter à se créer des profils alternatifs, ce qui va à rebours de la période où Google et Facebook voulait à l’inverse n’avoir que des profils dûment identifiés sous peine de suppression.
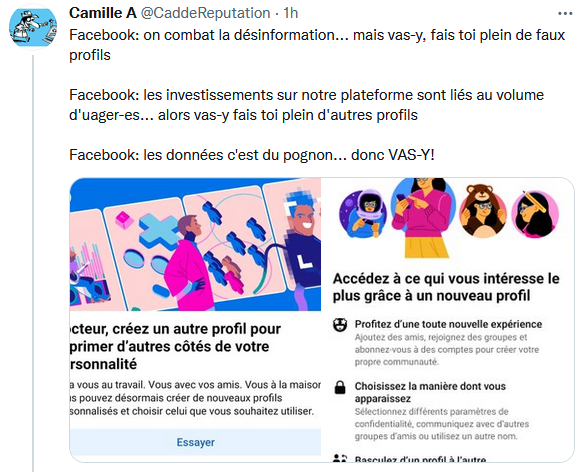
Ils avaient reculé sous la pression des usagers à l’époque. Désormais, ils vont dans le cheminement inverse, celui d’aller de plus en plus vers l’indexation de l’intime, du caché et de nos identités multiples.
Facebook s’est construit notamment sur le principe que Bruce Wayne était dans leur social graph, c’est-à-dire que tous les membres de l’intelligentsia américaine y figuraient puisque le modèle premier était de faire de Facebook un réseau social interuniversitaire.
Le futur président des États-Unis et des plus grosses entreprises allait nécessairement y figurer, un argument séduisant pour les investisseurs.
Mais désormais, il s’agit d’aller plus loin dans la bascule entre la réalité sociale et les alternatives identitaires.
Les limites algorithmiques et la faible volonté d’investir suffisamment pour éviter les problématiques de désinformation font qu’au final Facebook va renverser petit à petit le problème en solution.
Puisque les usagers peinent à distinguer le vrai du faux, la véracité factuelle de la manipulation, pourquoi ne pas en jouer ? Pourquoi ne pas devenir le lieu par excellence de ces basculements, pourquoi ne pas garder en son sein le plus longtemps possible l’usager qu’il soit dans un cadre professionnel, personnel, familial mais également passionnel et surtout secret.
Le syllogisme est simple :
Bruce Wayne est dans le graphe, mais il est aussi Batman.
Alors il faut que Batman soit dans le graphe.
Nous avons les moyens de savoir que Bruce et Batman sont les mêmes personnes…
Il en va de même pour chacun d’entre nous finalement. Nous ne sommes ni de riches industriels ni des super héros. Mais nous avons plusieurs identités en chacun de nous qu’il nous ait possible de « tabuler », pour reprendre l’expression de Yann Leroux.
Le metaverse, c’est justement l’extension de la problématique de l’indexation. C’est le renversement de la situation avec ce moment où les métadonnées deviennent plus importantes que les objets qui les qualifient.
Buckland avait bien montré cette tendance avec le fait que les systèmes de métadonnées en bibliothèques étaient devenus plus importants que les documents eux-mêmes :
« La première utilisation originelle des métadonnées est pour décrire des documents, et le nom metadata (au-delà ou avec des données) ainsi que sa définition populaire «données sur les données» sont basés sur cette utilisation. Une deuxième utilisation des métadonnées consiste à former des structures d’organisation au moyen desquelles des documents peuvent être organisés. Ces structures peuvent être utilisées à la fois pour rechercher des documents individuels ainsi que pour identifier des modèles au sein d’un groupe de documents. Le deuxième rôle des métadonnées implique une inversion de la relation entre document et métadonnées. Ces structures peuvent être considérées comme une infrastructure. » [1] (Buckland 2017, p.120)

Du coup, ce qui intéresse depuis toujours Facebook, c’est ce qui nous lie, pas uniquement une simple fiche identitaire qui n’a pas de valeur si elle est isolée. Créer des liens entre nous, c’est aussi étymologiquement l’objectif de la religion. En cela, Facebook conserve bien cet aspect « livre », mais son basculement progressif vers le « meta » marque clairement ce qui est le cas depuis très longtemps, la primeur des mécanismes classificatoires et le développement de superstructures pour parvenir à les gérer et les articuler.
On rentre donc clairement dans une phase qui est celle de l‘hyperdocumentation annoncée par Paul Otlet. Mais ce dernier espérait que la documentation soit un rempart contre les séparatismes en tout genre et un moyen de nous associer pour le progrès de l’humanité. Sauf que Facebook et son metaverse a autant besoin de nos associations que de nos dissociations pour poursuivre son expansion.

[1] Citation originale : « the first and original use of metadata is for describing documents, and the name metadata (beyond or with data) along with its popular definition, “data about data,” are based on this use. A second use of metadata is to form organizing structures by means of which documents can be arranged. These structures can be used both to search for individual documents and also to identify patterns within a population of documents. The second role of metadata involves an inversion of the relationship between document and metadata. These structures can be considered infrastructure. »